编译
在Go语言中,可以使用下述语句观察整个编译过程
go build -x main.go
在编译过程中,主要包含两个步骤
- 编译
将源代码文件编译为.o结尾的目标文件
- 链接
将目标文件合并为可执行文件
可执行文件在不同操作系统中规范不一样。linux系统中为ELF,windows系统中PE,macos系统中Mach-O
Linux 的可执行文件 ELF(Executable and Linkable Format)为例包含:
- ELF header
- Section header
- Sections
linux操作系统在解析可执行文件时候,首先解析ELF header,其次,加载文件至内存,最后,从entry point开始执行代码
编译
编译过程大致分为两个阶段,编译前端和编译后端口
编译前端:词法分析、语法分析、语义分析 编译后段:中间代码生成、中间代码优化、机器代码生成
- 词法分析
词法分析阶段,就是将文本文件中字符序列转换为单词(Token)序列的过程,从左至右地对源程序进行扫描,按照语言的词法规则识别各类单词,并产生相应单词的属性字 比如说:go语言中 换行符转为token就为 ‘ ; ‘ ‘ func ‘字符串转换token为 func int类型字符转换token为 INT等等
- 语法分析
语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等。 语法分析程序判断源程序在结构上是否正确。源程序的结构由上下文无关文法描述。语法分析程序可以用YACC等工具自动生成。
语法分析器会创建出语法分析树(AST)。一旦AST被创建出来,在后续的处理过程中,比如语义分析阶段,会添加一些信息
- 语义分析
语义分析是审查源程序有无语义错误,为代码生成阶段收集类型信息。比如语义分析的一个工作是进行类型审查,审查每个算符是 否具有语言规范允许的运算对象,当不符合语言规范时,编译程序应报告错误。如有的编译程序要对实数用作数组下标的情况报告错误。 又比如某些程序规定运算对象可被强制,那么当二目运算施于一整型和一实型对象时,编译程序应将整型转换为实型而不能认为是源程序的错误。
语义分析的地位:编译程序最实质性的工作;第一次对源程序的语义作出解释,引起源程序质的变化
- 中间代码生成与优化
将代码转化为静态单赋值形式的中间代码SSA SSA(Single Static Assignment)的两大要点是:
- Static: 每个变量只能赋值一次(因此应该叫常量更合适)
- Single: 每个表达式只能做一个简单运算,对于复杂的表达式ab+cd要拆分成: t0=ab; t1=cd; t2=t0+t1; 三个简单表达式;
链接
在链接过程中,最重要的就是进行虚拟地址重定位(Relocation) 在编译后,所有函数地址都是从 0 开始 每条指令是相对函数第一条指令的偏移 链接后,所有指令都有了全局唯一的地址
分析工具
- readelf
- dlv
- go tool compile -S
- go tool objdump
在linux系统中,可以使用工具readelf来找到Go进程的执行入口
readelf -h ./可执行文件名称
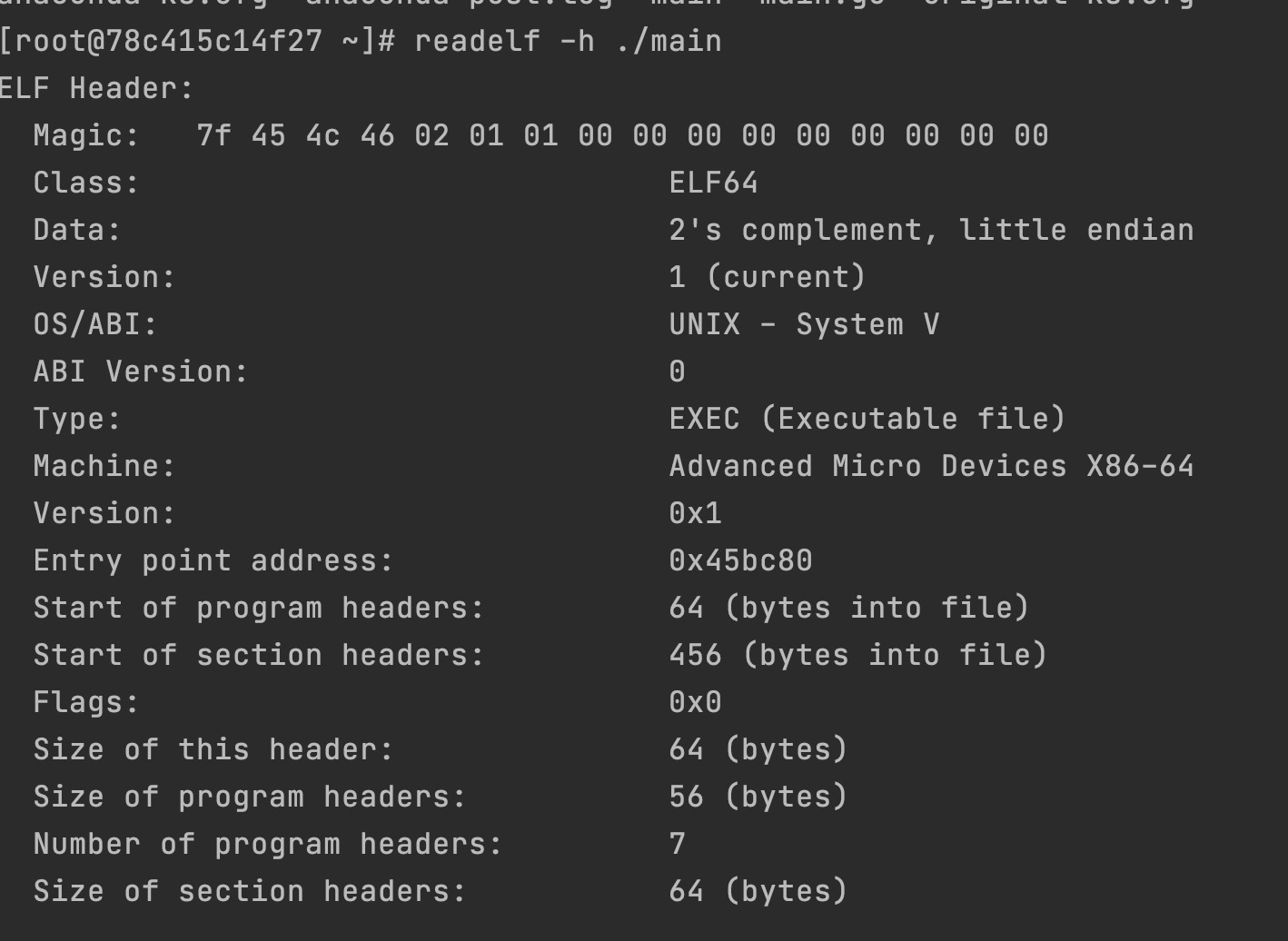
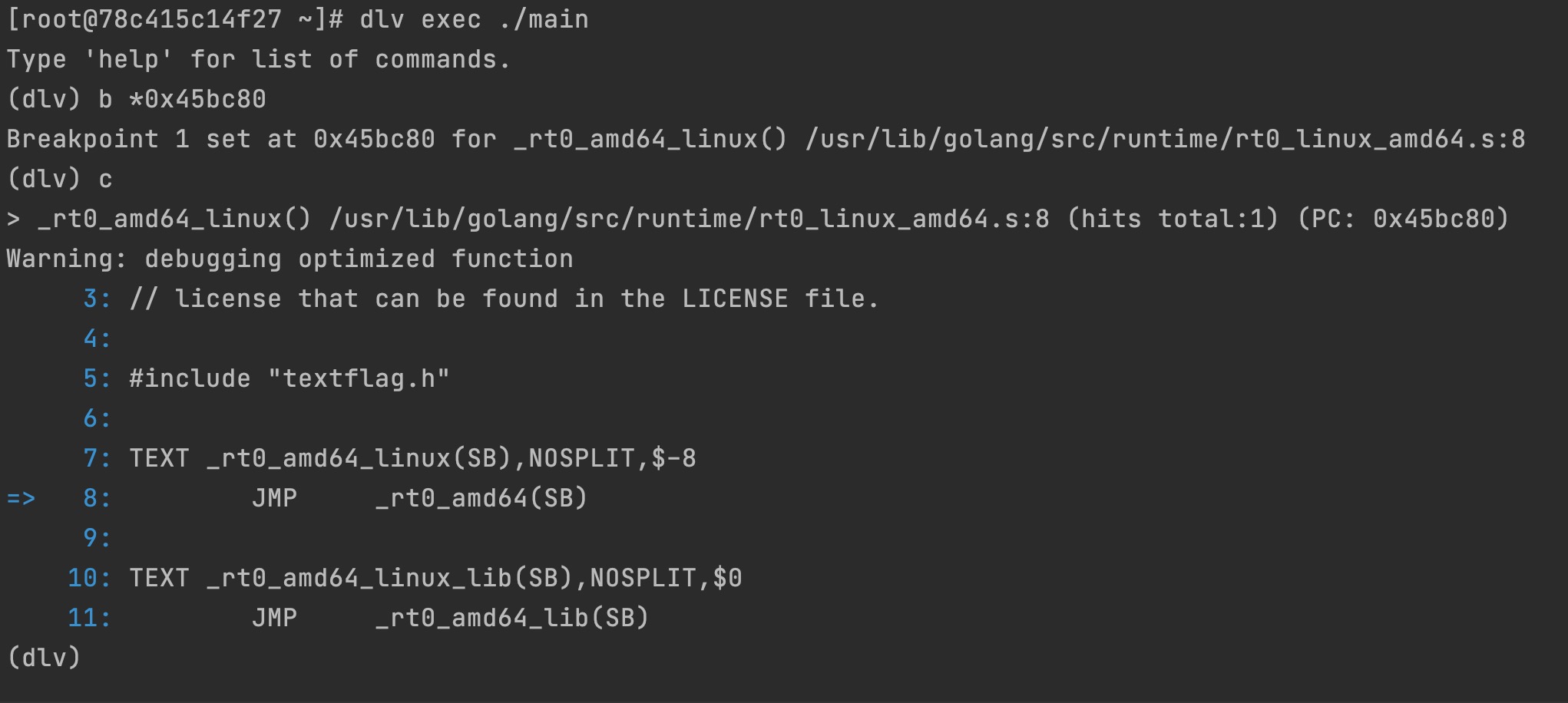
找到执行入口地址过后,就可使用dlv中的命令进行调试了
dlv exec ./可执行文件名称
b *内存地址 命令设置了一个断点,可多次标记
使用 c 命令,即为下一步,跳转到下一断点。
使用si到下一个目标位置,它比c的粒度更细,它就是执行一条汇编指令
使用disass 反汇编
也可以使用dlv工具 debug单个文件
dlv debug ./main.go
# 在函数main上打一个断点
b main.main
# 然后使用c命令,直接跳转到main.main
c
# 使用 bt查看执行到当前指令的调用栈
# 使用 frame 行号跳转到具体调用点
CPU 无法理解文本,只能执行一条一条的二进制机器码指令,每次执行完一条指令,pc寄存器就指向下一条继续执行
编译时查看:
go tool compile -S ./main.go | grep "main.go:5"
该命令会生成 .o 目标文件,并把目标的汇编内容输出
查看可执行文件
go tool objdump ./main -E |grep "main.go"