内存分配
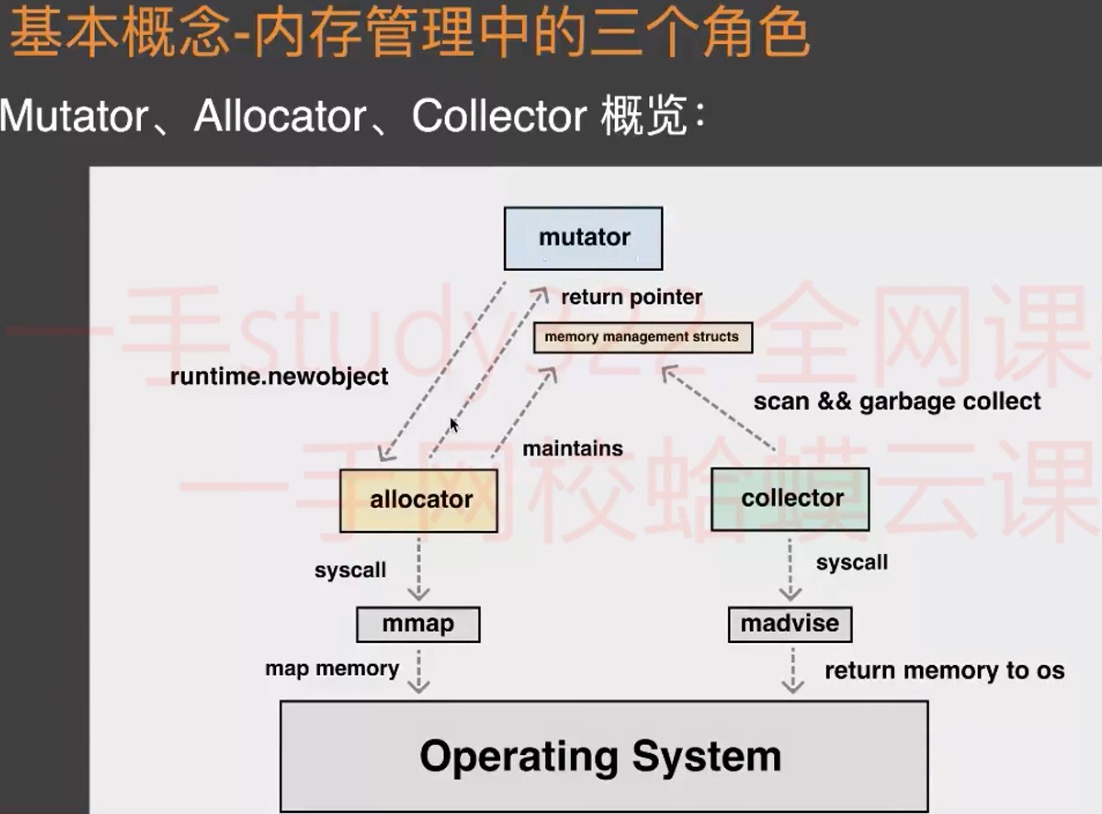
内存管理中的三个角色
- Mutator: fancy(花哨的)word for application,其实就是你写的应用程序,它会不断地修改对象 的引用关系,即对象图
- Allocator: 内存分配器,负责管理从操作系统中分配出的内存空间 malloc 其实底层就有一个内存分配器的实现(glibc中),tcmalloc是malloc 多线程改进版(malloc再分配的过程中是需要加锁的,tcmalloc在这个过程中做了优化,减少了锁竞争)。Go中实现类似tcmalloc
- Collector: 垃圾收集器,负责清理死对象,释放内存空间
对于进程的虚拟内存分配来说,最主要的部分是两块儿,一块儿是栈,一块儿是堆,栈从高地址往低地址减少,堆 由低地址往高地址增加。当两块儿重合时,就会发生oom。若,进程中存在多线程,那么就会存在多个线程特有的 栈空间和一块儿都能访问的公共空间,以及堆空间。
Allocator分配器有两种类型,一种是Bump/Sequential Allocator(线性分配器),一种是Free List Allocator(空闲链表)
线性分配器每次从内存中取一块儿出来,每取一次,指针后移。这样分配不好的地方在于会产生内存碎片。为了避免这种情况,使用空闲链表,将碎片的地址 链接起来。若内存再次分配,那么再次分配过后需重新维护链表
逃逸分析
Go语言在分配内存的时候,会做逃逸分析,会将某些需要多处访问的变量分配在堆上。可以使用相关工具查看逃逸分析数据
go build -gcflags="-m" main.go
若需要详细的数据,可以多加几个 ‘-m’
若想查看更多的逃逸分析代码:
- cmd/compile/internal/gc/escape.go
- https://github.com/golang/go/tree/master/test
空闲链表
空闲链表分配算法大致有四种
- First-Fit
遍历空闲链表,找到第一个符合条件的内存块儿,比如,现在需要分配10B的空间,就会一次遍历找到满足此 大小的内存块儿,切割出合适的大小用于分配,并将剩余的部分和空闲链表进行维护
- Next-Fit
分配过程和First-Fit相似,只是开始遍历的位置不同,First-Fit是从头开始,Next-Fit是从上次分配成功过后的位置开始,一直到 将整个链表遍历完成
- Beast-Fit
从第一个位置开始,找到匹配度(待分配的大小和内存块儿的大小)最高位置
- Segregated-Fit
将内存进行分级。将内存进行切割,按照8B、18B……等大小分成不同的集合。每次分配的时候,直接找到最相近的集合进行分配。 Go语言的内存分配器便是这种模式的一个改进版本,可以减少分配产生的内存碎片
malloc实现
malloc分配器的实现是线性分配器和空闲链表分配的结合

当待分配的内存小于128k的时候,通过一个叫brk的系统调用调整program break(堆的堆顶)位置来增长 当待分配的内存大于等于128k的时候,通过mmap从任意位置分配映射内存
未使用的内存块儿
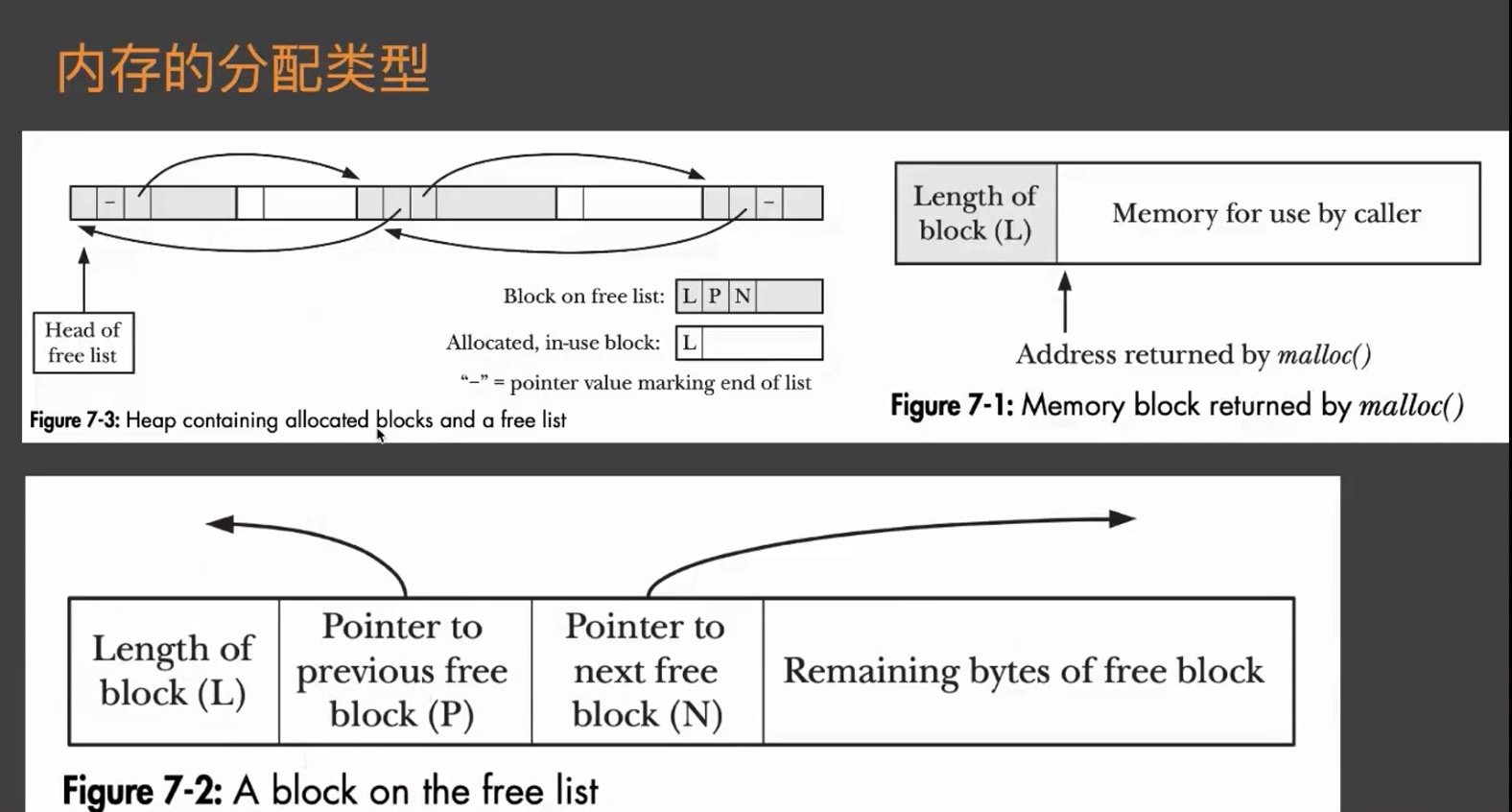
每个块儿包含的属性
- 当前块儿长度
- 指向前一个链表的指针
- 指向后一个链表的指针
- 具体数据
在使用中的内存块儿由两部分组成,一个是当前块儿的长度,以及后续可使用内存,调用malloc函数的时候 就会返回可使用内存的头部位置(不是包含当前块儿长度数据的位置)。后续释放内存的时候 会依赖块儿长度数据,也即是说,当调用malloc函数过后,修改了返回的指针位置,再去free的话,会有问题。 因为free会依赖此长度。
Go语言的内存分配
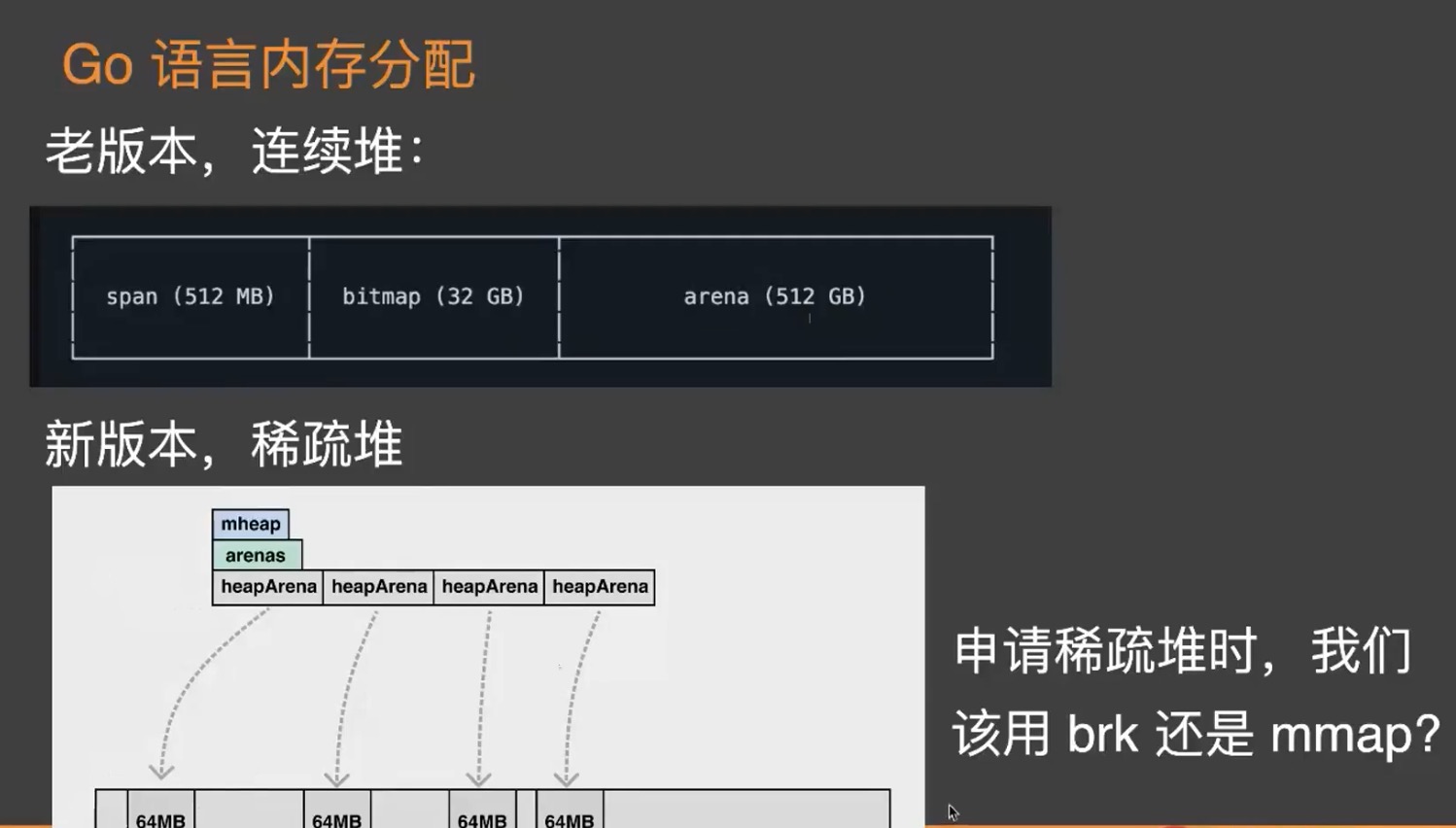
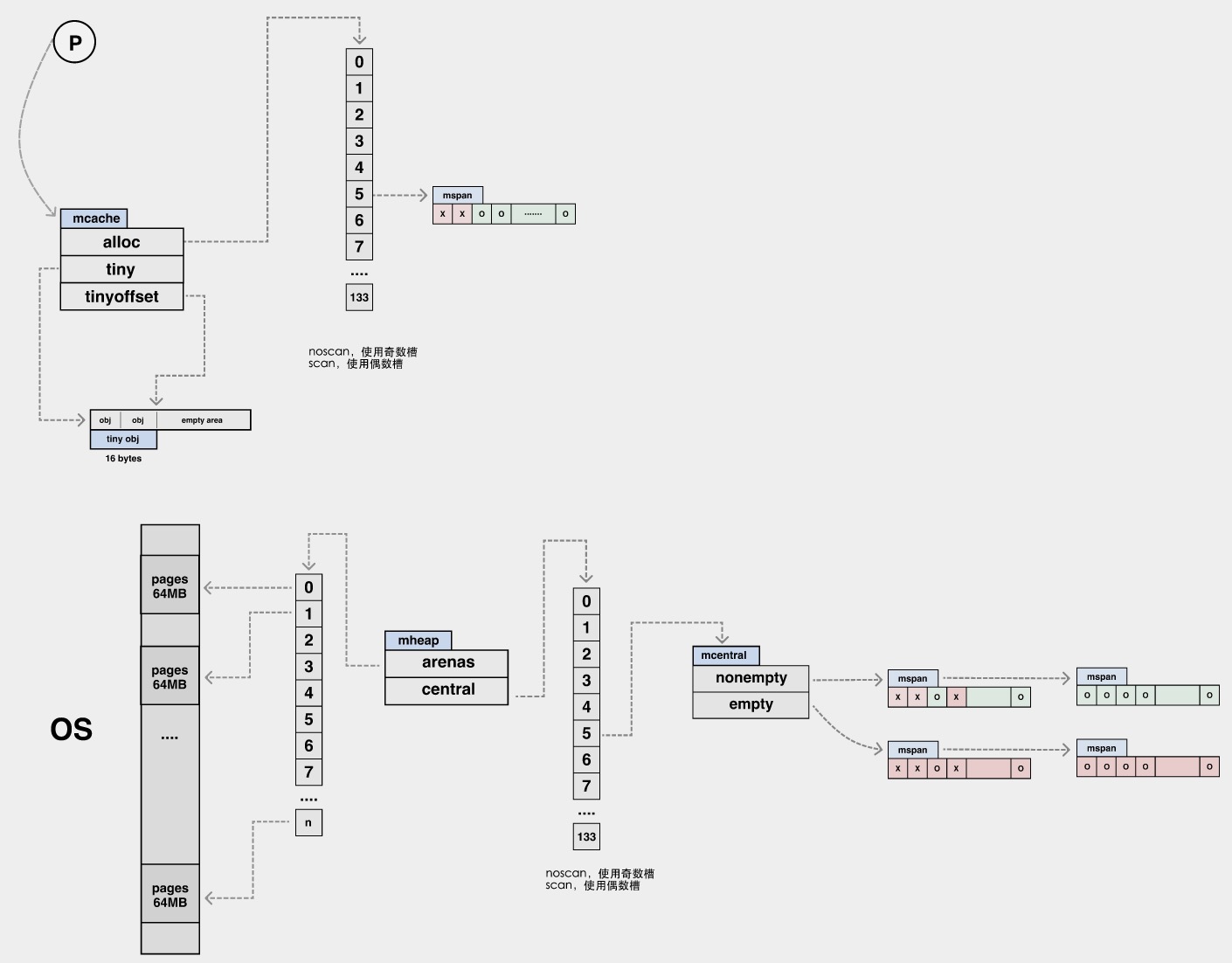
老版本的连续堆分配在和cgo配合的时候容易发生碰撞。所以后续进行了改进,将内存直接拆分成64M大小的非连续行的数据块儿进行链接。 这儿分配的时候使用mmap进行分配(分配非连续性地址)
Go内存申请流程
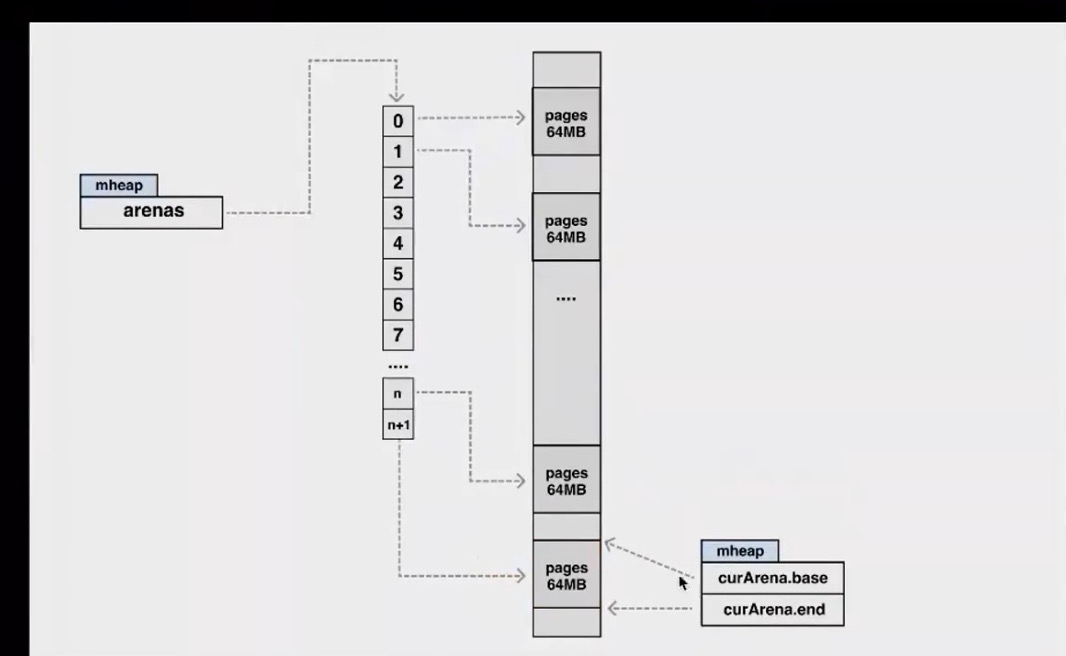
mheap会维护最一个内存块儿(heapArena)的起始位置,当分配的时候发现内存的地址大于了最后的内存结束位置,就会执行 mmap去申请一块儿新的内存,并重新维护mheap的信息。
内存分配逻辑
分配大小分类
- Tiny : size < 16 bytes && has no pointer(noscan)
-
Small : has pointer(scan) (size >= 16 bytes && size <= 32 kb) - Large : size > 32 KB
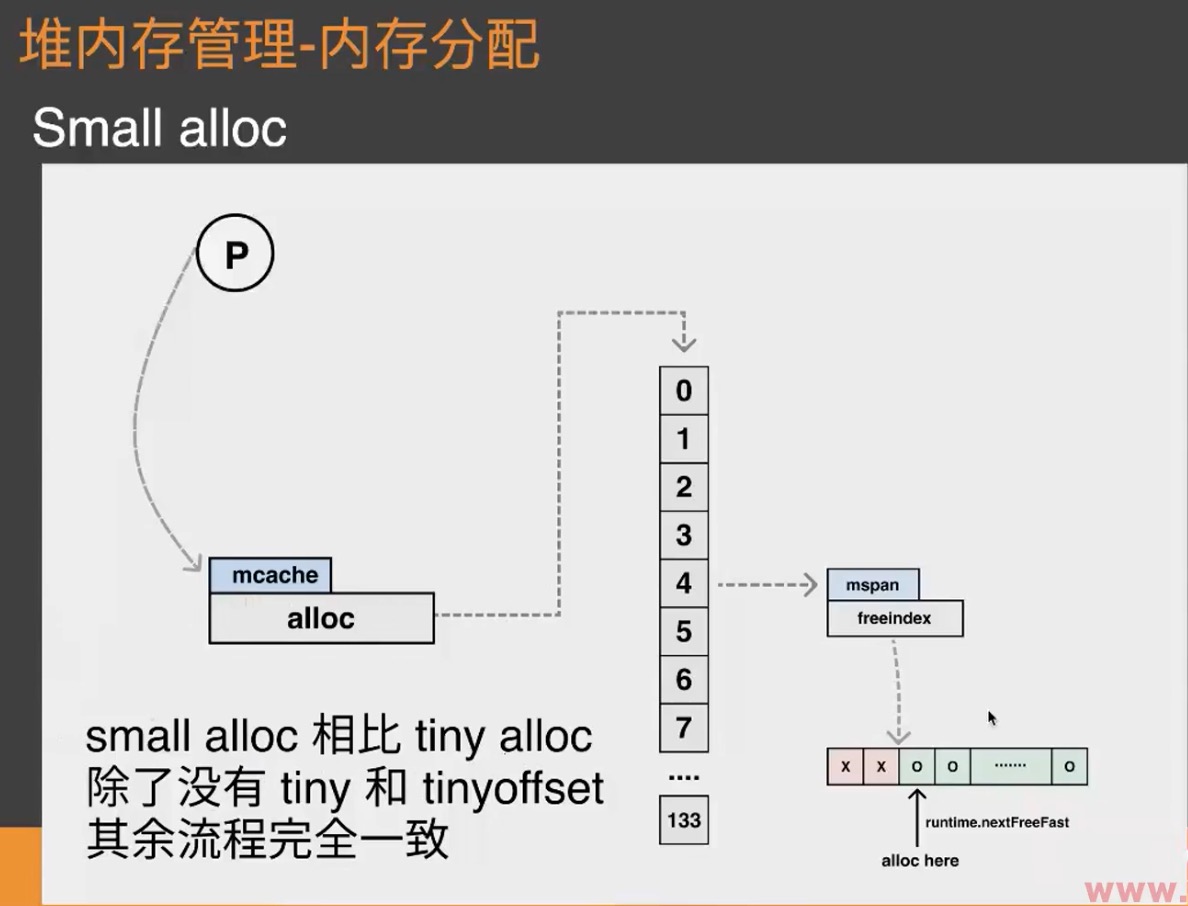
在Tiny 和 small类型分配中,会用到mcache这样一种数据结构
mcache -> mcentral -> mheap
mcache: 与P绑定,本地内存分配操作,不需要加锁。 mcentral: 中心分配缓存,分配时需要上锁,不同spanClass使用不同的锁。 mheap: 全局唯一,从OS申请内存,并修改其内存定义结构时, 需要加锁,是个全局锁。
mcentral中将从系统中获取的内存自行维护成了两块儿spanClass数组,一块儿为noempty,一块儿为empty。 他们都是mspan链表。
对于mspan数据结构来说,它类似于tcmalloc中的span。用来实现多级缓存。mspan的大小由sizeclass.go中定义,对于 特定的spanClass类型,它有特定的大小分配。其内存块儿为多个page页聚合而成,同时,将其按照spanClass定义的大小分为 多个element。每次进行内存分配的时候,按照待分配对象的大小,确定分配在alloc中的特定spanClass对应的位置。

mspan相关参考 https://www.sohu.com/a/300983903_657921
堆内存管理-内存分配
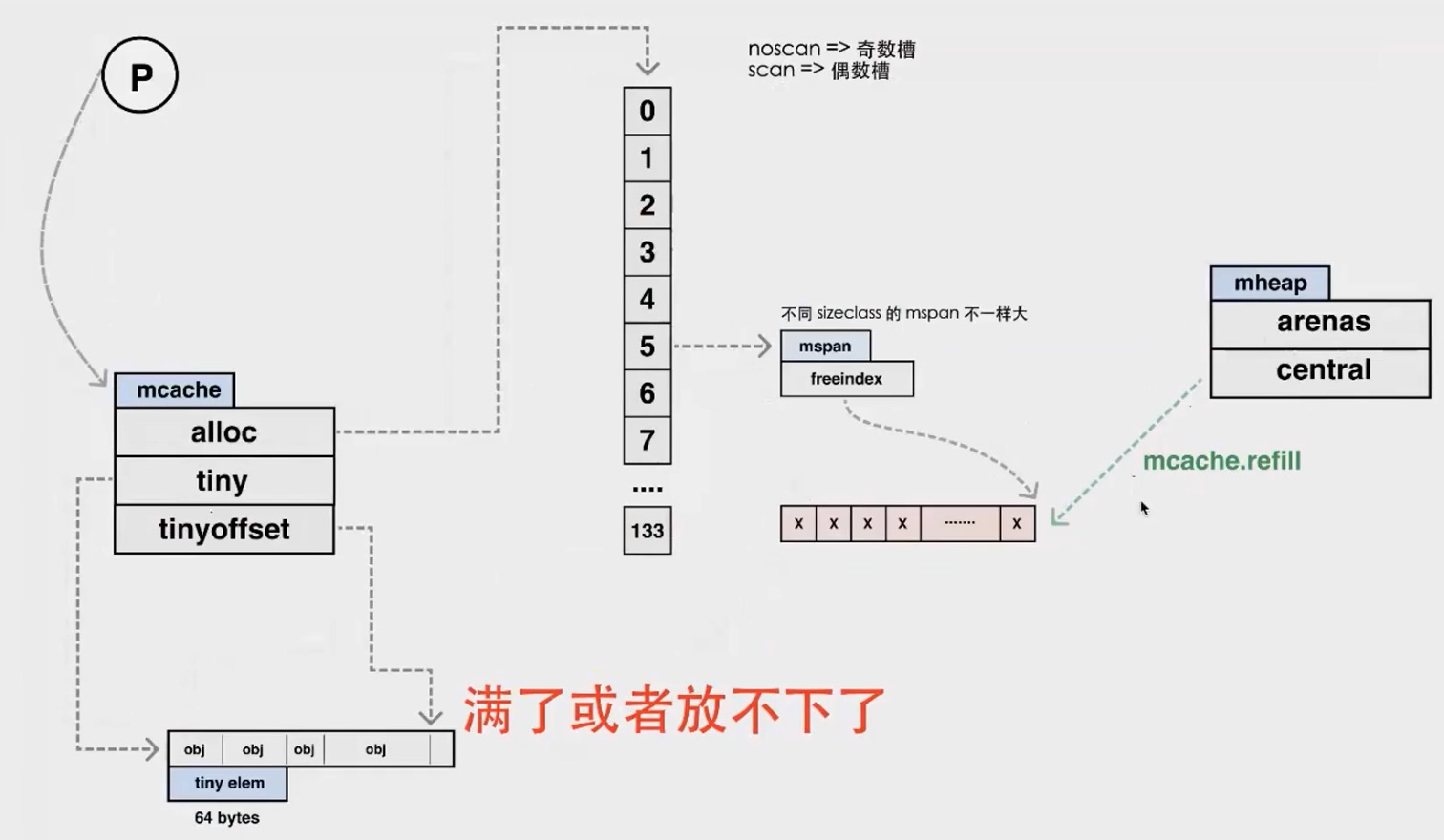
- Tiny 分配
Tiny allocator 分配器会组合多个tiny分配的请求(不包含指针的对象),将其分配在一个内存块儿内。当待分配的内存小于maxTinySize时 会使用Tiny allocator进行分配,当前设置的maxTinySize是16kb(可调整)。这个值设计的时候是有考虑的,没有使用8B,也没有使用32等。 当设置为8B的时候,是不会有内存浪费的,但是可以合并的次数就很少了,那么在内存回收等情况下,就没那么高的效率,当设置为32时,就可能会 造成4倍的浪费,极端情况下就是只有一个有用,剩下的所有内存都可以释放,但是Tiny allocator分配和回收都是按照一整块儿进行的。当该内存块儿 所有数据都不可达时,就进行回收,这个分配主要是针对小的string对象或者单独逃逸了的变量(比如某一个字段逃逸了) 在benchmark测试,使用 Tiny allocator可以降低12%分配数量,及20%的堆的大小
// tinySizeClass = _TinySizeClass = 2
tinySpanClass = spanClass(tinySizeClass<<1 | 1)
当Tiny allocator分配满时,会去alloc结构中获取内存块儿,alloc内部其实就是上述67中类型乘以2的结构。 对应的就是分别奇、偶67种类型。他们交替存在。对于noscan(无指针)的结构对象存在奇数槽当中,有指针结构存在偶数槽当中
Tiny allocator 在分配的时候获取的内存块是从alloc内部spanClass为5的mspan链表中获取的内存块儿,也就是每次 获取的32B大小的数据
当本地alloc对应spanClass内存满了,就会取全局中心分配缓存中获取(Refill)一个内存块儿,也就是mspan中的一个元素。这里 需要注意的是这个获取的内存块儿可能已经包含了数据,并不一定是全部空间。
Refill 流程: • 本地mcache没有时触发(mcache.refill) • 从mcentral里的non-empty链表中找(mcentral.cacheSpan) • 尝试sweep mcentral的empty,insert sweeped -> non- empty(mcentral.cacheSpan) • 增⻓ mcentral,尝试从 arena 获取内存(mcentral.grow) • arena 如果还是没有,向操作系统申请(mheap.alloc)
最终还是会将申请到的 mspan放在 mcache对应的alloc结构中
- Small alloc
- large alloc
大对象分配会直接越过 mcache、mcentral,直接从 mheap 进行相应数量的 page 分配。 pageAlloc 结构经过多个版本的变化,从:freelist -> treap -> radix tree,查找时间复杂度越来越低,结构越来越复杂