Go语言并发编程库
sync.Once
初始化方法必须且只能被调用一次 Do返回后,初始化一定已经执行完成
// Once is an object that will perform exactly one action.
type Once struct {
// 表明动作是否被执行
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
// Note: Here is an incorrect implementation of Do:
//
// if atomic.CompareAndSwapUint32(&o.done, 0, 1) {
// f()
// }
//
// Do guarantees that when it returns, f has finished.
// This implementation would not implement that guarantee:
// given two simultaneous calls, the winner of the cas would
// call f, and the second would return immediately, without
// waiting for the first's call to f to complete.
// This is why the slow path falls back to a mutex, and why
// the atomic.StoreUint32 must be delayed until after f returns.
if atomic.LoadUint32(&o.done) == 0 {
// Outlined slow-path to allow inlining of the fast-path.
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
sync.Pool
sync.Pool 是 Golang 内置的对象池技术,可用于缓存临时对象,避免因频繁建立临时对象所带来的消耗以及对 GC 造成的压力。 在许多知名的开源库中,都可以看到 sync.Pool 的大量使用。例如,HTTP 框架 Gin 用 sync.Pool 来复用每个请求都会创建的 gin.Context 对象。 在 grpc-Go、kubernates 等也都可以看到对 sync.Pool 的身影。 但需要注意的是,sync.Pool 缓存的对象随时可能被无通知的清除,因此不能将 sync.Pool 用于存储持久对象的场景
主要在两种场景使用
- 进程中的inuse_objects数过多,gc mark消耗大量CPU
进程中存活对象过多,在GC过程中,标记的时候就会消耗大量CPU
- 进程中的inuse_objects数过多,进程中RSS占用过高
比如,docker当中指定分配一定量的内存,对象数过多就会kill掉进程
请求生命周期开始时,pool.Get。请求结束时,pool.Put。在fasthttp中有大量应用
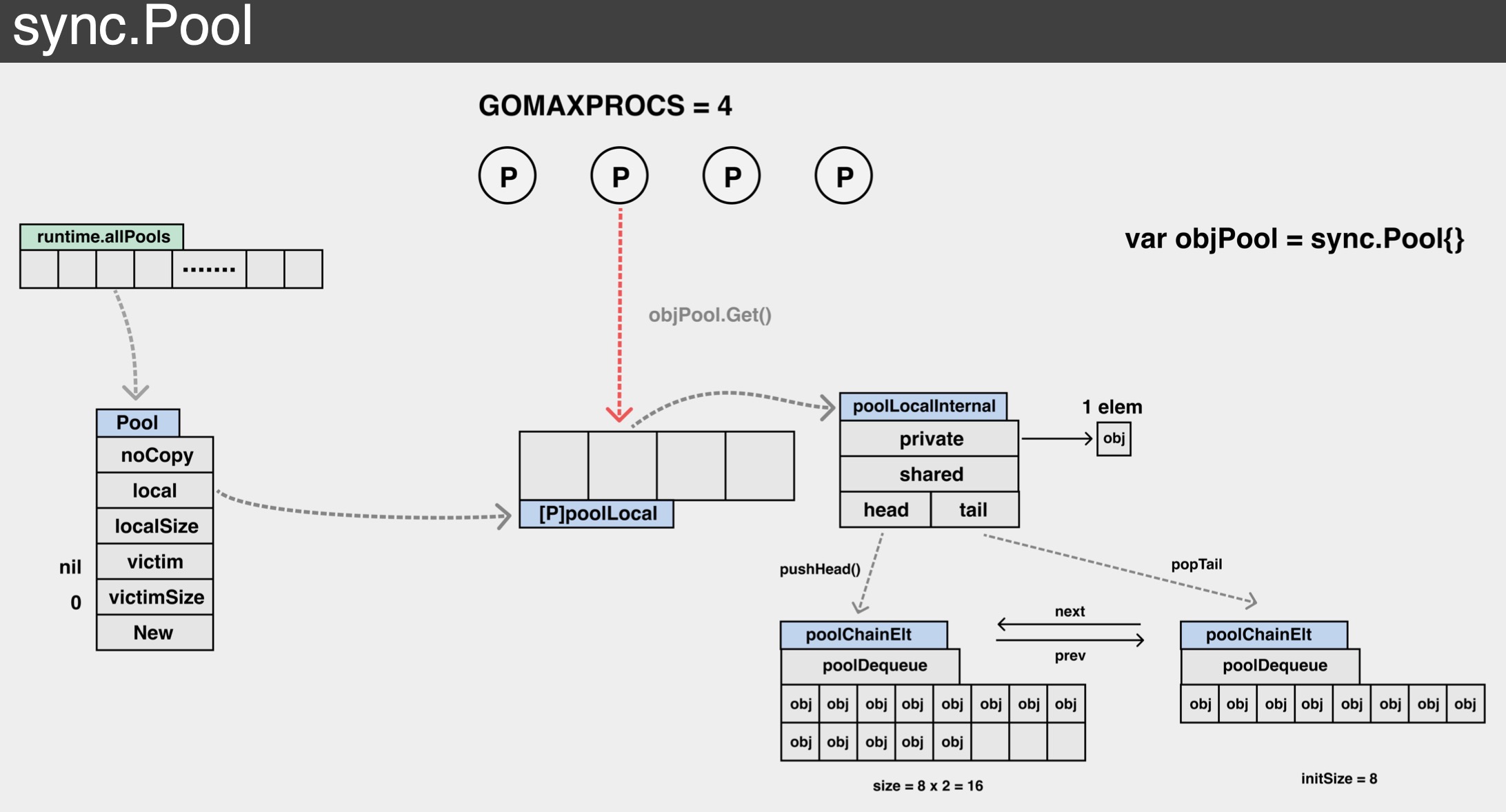
大致数据结构
// A Pool must not be copied after first use.
type Pool struct {
noCopy noCopy // 不可复制标志 pool在初次使用过后不能被复制
local unsafe.Pointer // 固定大小的poolLocal数组 actual type is [P]poolLocal
localSize uintptr // 数组大小
victim unsafe.Pointer // 上一次发生GC后的local拷贝
victimSize uintptr // 上一次发生GC后的local拷贝数组大小
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
// 创建的方法
New func() interface{}
}
local 是个数组,长度为 P 的个数。其元素类型是 poolLocal。这里面存储着各个 P 对应的本地对象池。可以近似的看做 [P]poolLocal。 localSize代表 local 数组的长度。因为 P 可以在运行时通过调用 runtime.GOMAXPROCS 进行修改, 因此我们还是得通过 localSize 来对应 local 数组的长度。 * New 就是用户提供的创建对象的函数。这个选项也不是必需。当不填的时候,Get 有可能返回 nil。
其他几个字段我们暂时不用太过关心,这里先简单介绍下: victim 和 victimSize。这一对变量代表了上一轮清理前的对象池,其内容语义 local 和 localSize 一致。victim 的作用还会在下面详细介绍到。 noCopy 是 Golang 源码中禁止拷贝的检测方法。
由于每个 P 都有自己的一个本地对象池 poolLocal,Get 和 Put 操作都会优先存取本地对象池。由于 P 的特性,操作本地对象池的 时候整个并发问题就简化了很多,可以尽量避免并发冲突
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
// Local per-P Pool appendix.
type poolLocalInternal struct {
private interface{} // Can be used only by the respective P.
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
type poolChain struct {
// head is the poolDequeue to push to. This is only accessed
// by the producer, so doesn't need to be synchronized.
head *poolChainElt
// tail is the poolDequeue to popTail from. This is accessed
// by consumers, so reads and writes must be atomic.
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
next, prev *poolChainElt
}
type poolDequeue struct {
headTail uint64
vals []eface
}
poolLocal中 pad 变量的作用是用来解决false sharing(伪共享)。先看poolLocalInternal 的定义 其中每个本地对象池,都会包含两项: private 私有变量。Get 和 Put 操作都会优先存取 private 变量 如果 private 变量可以满足情况,则不再深入进行其他的复杂操作。 shared变量其类型为 poolChain。 从名字不难看出这个是链表结构,这个就是 P 的本地对象池了
为什么 poolChain 是这么一个链表 + ring buffer 的复杂结构呢?简单的每个链表项为单一元素不行吗? 使用 ring buffer 是因为它有以下优点:
- 预先分配好内存,且分配的内存项可不断复用。
- 由于ring buffer 本质上是个数组,是连续内存结构,非常利于 CPU Cache。在访问poolDequeue 某一项时 其附近的数据项都有可能加载到统一 Cache Line 中,访问速度更快。
ring buffer 的这两个特性,非常适合于 sync.Pool的应用场景。
我们再注意看一个细节,poolDequeue 作为一个 ring buffer,自然需要记录下其 head 和 tail 的值。 但在 poolDequeue 的定义中,head 和 tail 并不是独立的两个变量,只有一个 uint64 的 headTail 变量。 这是因为 headTail 变量将 head 和 tail 打包在了一起:其中高 32 位是 head 变量,低 32 位是 tail 变量
对于一个 poolDequeue 来说,可能会被多个 P 同时访问,这个时候就会带来并发问题。 例如:当 ring buffer 空间仅剩一个的时候,即 head - tail = 1。 如果多个 P 同时访问 ring buffer,在没有任何并发措施的情况下,两个 P 都可能会拿到对象,这肯定是不符合预期的。 在不引入 Mutex 锁的前提下,sync.Pool 是怎么实现的呢?sync.Pool 利用了 atomic 包中的 CAS 操作。两个 P 都可能会拿到对象,但在最终设置 headTail 的时候 只会有一个 P 调用 CAS 成功,另外一个 CAS 失败
atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2)
在更新 head 和 tail 的时候,也是通过原子变量 + 位运算进行操作的。例如,当实现 head++ 的时候,需要通过以下代码实现
const dequeueBits = 32
atomic.AddUint64(&d.headTail, 1<<dequeueBits)
Put 的实现
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
// 会标记当前不可抢占
l, _ := p.pin()
if l.private == nil {
l.private = x
x = nil
}
if x != nil {
l.shared.pushHead(x)
}
// 去除不可抢占
runtime_procUnpin()
}
从以上代码可以看到,在 Put 函数中首先调用了 pin()。pin 函数非常重要,它有三个作用:
- 初始化或者重新创建local数组。 当 local 数组为空,或者和当前的 runtime.GOMAXPROCS 不一致时,将触发重新创建 local 数组,以和 P 的个数保持一致。
- 取当前 P 对应的本地缓存池 poolLocal
- 防止当前 P 被抢占。这点非常重要。在 Go 1.14 以后,Golang 实现了抢占式调度:一个 goroutine 占用 P 时间过长,将会被调度器强制挂起。如果一个 goroutine 在执行 Put 或者 Get 期间被挂起 有可能下次恢复时,绑定就不是上次的 P 了。那整个过程就会完全乱掉。因此,这里使用了 runtime 包里面的 procPin,暂时不允许 P 被抢占
接着,Put 函数会优先设置当前 poolLocal 私有变量 private。如果设置私有变量成功,那么将不会往 shared 缓存池写了。这样操作效率会更高效。 如果私有变量之前已经设置过了,那就只能往当前 P 的本地缓存池 poolChain 里面写了。我们接下来看下,sync.Pool 的每个 P 的内部缓存池 poolChain 是怎么实现的。 在 Put 的时候,会去直接取 poolChain 的链表头元素 HEAD: 如果 HEAD 不存在 ,则新建一个 buffer 长度为 8 的 poolDequeue,并将对象放置在里面。 如果 HEAD 存在,且 buffer 尚未满,则将元素直接放置在 poolDequeue 中。 * 如果 HEAD 存在,但 buffer 满了,则新建一个新的 poolDequeue,长度为上个 HEAD 的 2 倍。同时,将 poolChain 的 HEAD 指向新的元素。 Put 的过程比较简单,整个过程不需要和其他 P 的 poolLocal 进行交互
Get 的实现
func (p *Pool) Get() interface{} {
l, pid := p.pin()
x := l.private
l.private = nil
if x == nil {
// 首先获取本地数据
//
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
runtime_procUnpin()
if x == nil && p.New != nil {
x = p.New()
}
return x
}
Get 函数会尝试从当前 P 的 本地对象池 poolChain 中获取对象。从当前 P 的 poolChain 中取数据时,是从链表头部开始取数据。 具体来说,先取位于链表头的 poolDequeue,然后从 poolDequeue 的头部开始取数据
如果从当前 P 的 poolChain 取不到数据,意味着当前 P 的缓存池为空,那么将尝试从其他 P 的缓存池中 窃取对象。这也对应 getSlow 函数的内部实现
for i := 0; i <int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
在 getSlow 函数,会将当前 P 的索引值不断递增,逐个尝试从其他 P 的 poolChain 中取数据。注意,当尝试从其他 P 的 poolChain 中取数据时,是从链表尾部开始取的
在对其他 P 的 poolChain 调用 popTail,会先取位于链表尾部的 poolDequeue,然后从 poolDequeue 的尾部开始取数据。 如果从这个 poolDequeue 中取不到数据,则意味着该 poolDequeue 为空,则直接从该 poolDequeue 从 poolChain 中移除 同时尝试下一个 poolDequeue。 如果从其他 P 的本地对象池,也拿不到数据。接下来会尝试从 victim 中取数据。上文讲到 victim 是上一轮被清理的对象池 从 victim 取对象也是 popTail 的方式。最后,如果所有的缓存池都都没有数据了,这个时候会调用用户设置的 New 函数,创建一个新的对象
sync.Pool 在设计的时候,当操作本地的 poolChain 时,无论是 push 还是 pop,都是从头部开始。而当从其他 P 的 poolChain 获取数据,只能从尾部 popTail 取。这样可以尽量减少并发冲突
对象的清理
sync.Pool 没有对外开放对象清理策略和清理接口。我们上面讲到,当窃取其他 P 的对象时,会逐步淘汰已经为空的 poolDequeue。但除此之外,sync.Pool 一定也还有其他的对象清理机制,否则对象池将可能会无限制的膨胀下去,造成内存泄漏。
Golang 对 sync.Pool 的清理逻辑非常简单粗暴。首先每个被使用的 sync.Pool,都会在初始化阶段被添加到全局变量 allPools []*Pool 对象中。Golang 的 runtime 将会在 每轮 GC 前,触发调用 poolCleanup 函数,清理 allPools。代码逻辑如下:
func poolCleanup() {
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
oldPools, allPools = allPools, nil
}
这里需要正式介绍下 sync.Pool 的 victim(牺牲者) 机制,我们在 Get 函数的对象窃取逻辑中也有提到 victim。
在每轮 sync.Pool 的清理中,暂时不会完全清理对象池,而是将其放在 victim 中。等到下一轮清理,才完全清理掉 victim。也就是说,每轮 GC 后 sync.Pool 的对象池都会转移到 victim 中,同时将上一轮的 victim 清空掉。
为什么这么做呢? 这是因为 Golang 为了防止 GC 之后 sync.Pool 被突然清空,对程序性能造成影响。因此先利用 victim 作为过渡,如果在本轮的对象池中实在取不到数据,也可以从 victim 中取,这样程序性能会更加平滑。
sync.Pool 的性能之道
- 利用 GMP 的特性,为每个 P 创建了一个本地对象池 poolLocal,尽量减少并发冲突。
- 每个 poolLocal 都有一个 private 对象,优先存取 private 对象,可以避免进入复杂逻辑。
- 在 Get 和 Put 期间,利用 pin 锁定当前 P,防止 goroutine 被抢占,造成程序混乱。
- 在获取对象期间,利用对象窃取的机制,从其他 P 的本地对象池以及 victim 中获取对象。
- 充分利用 CPU Cache 特性,提升程序性能。
semaphore
Go语言中,semaphore是锁实现的基础,是所有同步原语的基础设置
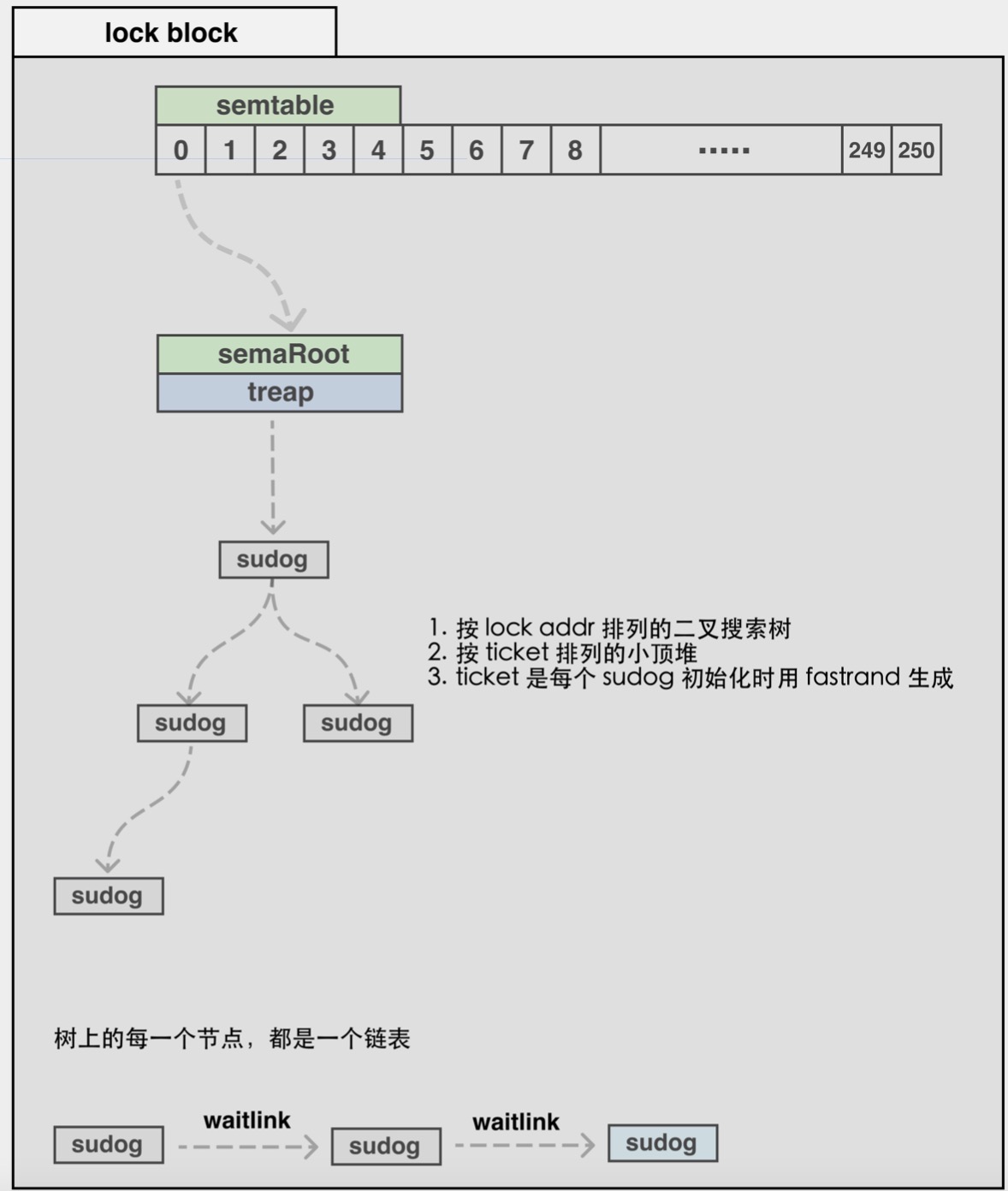
// go/src/runtime/sema.go
// 用于sync.Mutex的异步信号量。
// semaRoot拥有一个具有不同地址(s.elem)的sudog平衡树。
// 每个sudog都可以(通过s.waitlink)指向一个列表,在相同地址上等待的其他sudog。
// 对具有相同地址的sudog内部列表进行的操作全部为O(1)。顶层semaRoot列表的扫描为O(log n),
// 其中,n是阻止goroutines的不同地址的数量,通过他们散列到给定的semaRoot。
type semaRoot struct {
lock mutex
// waiters的平衡树的根节点
treap *sudog
// waiters的数量,读取的时候无所
nwait uint32
}
// Prime to not correlate with any user patterns.
const semTabSize = 251
var semtable [semTabSize]struct {
root semaRoot
pad [cpu.CacheLinePadSize - unsafe.Sizeof(semaRoot{})]byte
}
type sudog struct {
// 以下字段受hchan保护
g *g
// isSelect 表示 g 正在参与一个 select, so
// 因此 g.selectDone 必须以 CAS 的方式来获取wake-up race.
isSelect bool
next *sudog
prev *sudog
elem unsafe.Pointer // 数据元素(可能指向栈)
// 以下字段不会并发访问。
// 对于通道,waitlink只被g访问。
// 对于信号量,所有字段(包括上面的字段)
// 只有当持有一个semroot锁时才被访问。
acquiretime int64
releasetime int64
ticket uint32
parent *sudog //semaRoot 二叉树
waitlink *sudog // g.waiting 列表或 semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}
sync.Mutex
Go 语言的 sync.Mutex 由两个字段 state 和 sema 组成。其中 state 表示当前互斥锁的状态,而 sema 是用于控制锁状态的信号量,也既是上述 提到的semaphore。两个加起来只占 8 字节空间的结构体表示了 Go 语言中的互斥锁
type Mutex struct {
state int32
sema uint32
}
state字段表示锁状态,它的构成比较复杂。最低三位分别表示 mutexLocked、mutexWoken 和 mutexStarving,剩下的位置用来表示当前有多少个 Goroutine 在等待互斥锁的释放
- mutexLocked : 表示互斥锁的锁定状态
- mutexWoken : 表示从正常模式被唤醒
- mutexStarving : 当前的互斥锁进入饥饿状态
- 剩余位(waitersCount) : 当前互斥锁上等待的 Goroutine 个数
sync.Mutex 有两种模式 — 正常模式和饥饿模式
在正常模式下,锁的等待者会按照先进先出的顺序获取锁。但是刚被唤起的 Goroutine 与新创建的 Goroutine 竞争时,大概率会获取不到锁,为了减少这种情况的出现 一旦 Goroutine 超过 1ms 没有获取到锁,它就会将当前互斥锁切换饥饿模式,防止部分 Goroutine 被饿死
饥饿模式是在 Go 语言在 1.9引入。目的是保证互斥锁的公平性。
在饥饿模式中,互斥锁会直接交给等待队列最前面的 Goroutine。新的 Goroutine 在该状态下不能获取锁、也不会进入自旋状态,它们只会在队列的末尾等待。如果一个 Goroutine 获得了互斥锁并且它在队列的末尾或者它等待的时间少于 1ms,那么当前的互斥锁就会切换回正常模式。
与饥饿模式相比,正常模式下的互斥锁能够提供更好地性能,饥饿模式的能避免 Goroutine 由于陷入等待无法获取锁而造成的高尾延时
加锁/解锁流程
// A Locker represents an object that can be locked and unlocked.
type Locker interface {
Lock()
Unlock()
}
互斥锁的加锁过程比较复杂,它涉及自旋、信号量以及调度等概念
- 如果互斥锁处于初始化状态,会通过置位 mutexLocked 加锁
- 如果互斥锁处于 mutexLocked 状态并且在普通模式下工作,会进入自旋,执行 30 次 PAUSE 指令消耗 CPU 时间等待锁的释放
- 如果当前 Goroutine 等待锁的时间超过了 1ms,互斥锁就会切换到饥饿模式
- 互斥锁在正常情况下会通过 runtime.sync_runtime_SemacquireMutex 将尝试获取锁的 Goroutine 切换至休眠状态,等待锁的持有者唤醒
- 如果当前 Goroutine 是互斥锁上的最后一个等待的协程或者等待的时间小于 1ms,那么它会将互斥锁切换回正常模式
互斥锁的解锁过程
- 当互斥锁已经被解锁时,调用 sync.Mutex.Unlock 会直接抛出异常
- 当互斥锁处于饥饿模式时,将锁的所有权交给队列中的下一个等待者,等待者会负责设置 mutexLocked 标志位
- 当互斥锁处于普通模式时,如果没有 Goroutine 等待锁的释放或者已经有被唤醒的 Goroutine 获得了锁,会直接返回;在其他情况下会通过 sync.runtime_Semrelease 唤醒对应的 Goroutine
RWMutex
读写互斥锁 sync.RWMutex 是细粒度的互斥锁,它不限制资源的并发读,但是读写、写写操作无法并行执行
sync.RWMutex 中总共包含以下 5 个字段
type RWMutex struct {
w Mutex
writerSem uint32
readerSem uint32
readerCount int32
readerWait int32
}
- w — 复用互斥锁提供的能力
- writerSem 和 readerSem — 分别用于写等待读和读等待写
- readerCount 存储了当前正在执行的读操作数量
- readerWait 表示当写操作被阻塞时等待的读操作个数
写锁
当资源的使用者想要获取写锁时,需要调用 sync.RWMutex.Lock 方法
func (rw *RWMutex) Lock() {
rw.w.Lock()
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
}
- 调用结构体持有的 sync.Mutex 结构体的 sync.Mutex.Lock 阻塞后续的写操作。因为互斥锁已经被获取,其他 Goroutine 在获取写锁时会进入自旋或者休眠
- 调用 sync/atomic.AddInt32 函数阻塞后续的读操作
- 如果仍然有其他 Goroutine 持有互斥锁的读锁,该 Goroutine 会调用。runtime.sync_runtime_SemacquireMutex 进入休眠状态等待所有读锁所有者执行结束后释放 writerSem 信号量将当前协程唤醒
写锁的释放会调用 sync.RWMutex.Unlock
func (rw *RWMutex) Unlock() {
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
throw("sync: Unlock of unlocked RWMutex")
}
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
rw.w.Unlock()
}
- 调用 sync/atomic.AddInt32 函数将 readerCount 变回正数,释放读锁
- 通过 for 循环释放所有因为获取读锁而陷入等待的 Goroutine
- 调用 sync.Mutex.Unlock 释放写锁
获取写锁时会先阻塞写锁的获取,后阻塞读锁的获取,这种策略能够保证读操作不会被连续的写操作『饿死』
读锁
读锁的加锁方法 sync.RWMutex.RLock 很简单,该方法会通过 sync/atomic.AddInt32 将 readerCount
func (rw *RWMutex) RLock() {
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
}
- 如果该方法返回负数 — 其他 Goroutine 获得了写锁,当前 Goroutine 就会调用 runtime.sync_runtime_SemacquireMutex 陷入休眠等待锁的释放
- 如果该方法的结果为非负数 — 没有 Goroutine 获得写锁,当前方法会成功返回
当 Goroutine 想要释放读锁时,会调用如下所示的 sync.RWMutex.RUnlock 方法
func (rw *RWMutex) RUnlock() {
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
rw.rUnlockSlow(r)
}
}
该方法会先减少正在读资源的 readerCount 整数,根据 sync/atomic.AddInt32 的返回值不同会分别进行处理:
- 如果返回值大于等于零 — 读锁直接解锁成功
- 如果返回值小于零 — 有一个正在执行的写操作,在这时会调用sync.RWMutex.rUnlockSlow 方法
func (rw *RWMutex) rUnlockSlow(r int32) {
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
throw("sync: RUnlock of unlocked RWMutex")
}
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
sync.RWMutex.rUnlockSlow 会减少获取锁的写操作等待的读操作数 readerWait 并在所有读操作都被释放之后触发写操作的信号量 writerSem 该信号量被触发时,调度器就会唤醒尝试获取写锁的 Goroutine
虽然读写互斥锁 sync.RWMutex 提供的功能比较复杂,但是因为它建立在 sync.Mutex 上,所以实现会简单很多。我们总结一下读锁和写锁的关系
- 调用 sync.RWMutex.Lock 尝试获取写锁时
- 每次 sync.RWMutex.RUnlock 都会将 readerCount 其减一,当它归零时该 Goroutine 会获得写锁
- 将 readerCount 减少 rwmutexMaxReaders 个数以阻塞后续的读操作
- 调用 sync.RWMutex.Unlock 释放写锁时,会先通知所有的读操作,然后才会释放持有的互斥锁
sync.WaitGroup
sync.WaitGroup 可以等待一组 Goroutine 的返回,一个比较常见的使用场景是批量发出 RPC 或者 HTTP 请求
sync.WaitGroup 结构体中只包含两个成员变量
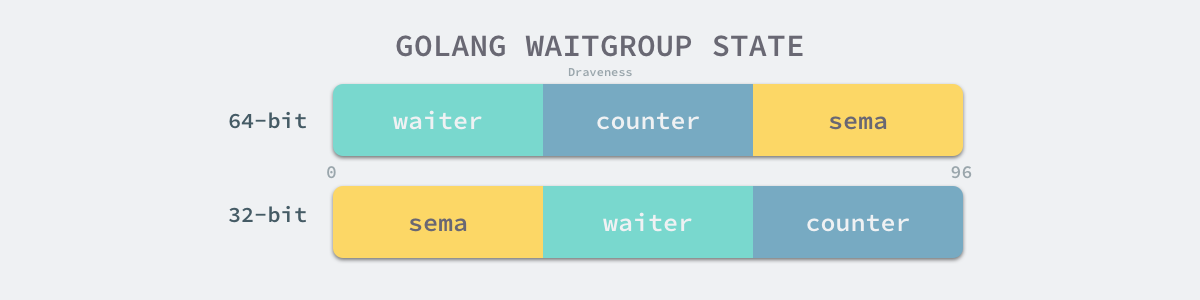
type WaitGroup struct {
noCopy noCopy
state1 [3]uint32
}
- noCopy — 保证 sync.WaitGroup 不会被开发者通过再赋值的方式拷贝
- state1 — 存储着状态和信号量
sync.noCopy 是一个特殊的私有结构体,tools/go/analysis/passes/copylock 包中的分析器会在编译期间检查被拷贝的变量中是否包含 sync.noCopy 或者实现了 Lock 和 Unlock 方法,如果包含该结构体或者实现了对应的方法就会报错
sync.WaitGroup` 结构体中还包含一个总共占用 12 字节的数组,这个数组会存储当前结构体的状态,在 64 位与 32 位的机器上表现也非常不同
sync.WaitGroup 对外暴露了三个方法 — sync.WaitGroup.Add、sync.WaitGroup.Wait 和 sync.WaitGroup.Done。
因为其中的 sync.WaitGroup.Done 只是向 sync.WaitGroup.Add 方法传入了 -1,所以我们重点分析另外两个方法,即 sync.WaitGroup.Add 和 sync.WaitGroup.Wait
func (wg *WaitGroup) Add(delta int) {
statep, semap := wg.state()
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32)
w := uint32(state)
if v < 0 {
panic("sync: negative WaitGroup counter")
}
if v > 0 || w == 0 {
return
}
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
sync.WaitGroup.Add 可以更新 sync.WaitGroup 中的计数器 counter。虽然 sync.WaitGroup.Add 方法传入的参数可以为负数,但是计数器只能是非负数,一旦出现负数就会发生程序崩溃。当调用计数器归零,即所有任务都执行完成时,才会通过 sync.runtime_Semrelease 唤醒处于等待状态的 Goroutine。
sync.WaitGroup 的另一个方法 sync.WaitGroup.Wait 会在计数器大于 0 并且不存在等待的 Goroutine 时,调用 runtime.sync_runtime_Semacquire 陷入睡眠
func (wg *WaitGroup) Wait() {
statep, semap := wg.state()
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32)
if v == 0 {
return
}
if atomic.CompareAndSwapUint64(statep, state, state+1) {
runtime_Semacquire(semap)
if +statep != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
return
}
}
}
当 sync.WaitGroup 的计数器归零时,陷入睡眠状态的 Goroutine 会被唤醒,上述方法也会立刻返回
sync.Map
优化点
- 空间换时间。 通过冗余的两个数据结构(read、dirty),实现加锁对性能的影响
- 使用只读数据(read),避免读写冲突
- 动态调整,miss次数多了之后,将dirty数据提升为read
- double-checking
- 延迟删除。 删除一个键值只是打标记,只有在提升dirty的时候才清理删除的数据
- 优先从read读取、更新、删除,因为对read的读取不需要锁
基础结构
type Map struct {
// 当涉及到dirty数据的操作的时候,需要使用这个锁
mu Mutex
// 一个只读的数据结构,因为只读,所以不会有读写冲突。
// 所以从这个数据中读取总是安全的。
// 实际上,实际也会更新这个数据的entries,如果entry是未删除的(unexpunged),
// 并不需要加锁。如果entry已经被删除了,需要加锁,以便更新dirty数据。
read atomic.Value // readOnly
// dirty数据包含当前的map包含的entries,它包含最新的entries(包括read中未删除的数据,虽有冗余,但是提升dirty字段为read的时候非常快,不用一个一个的复制,而是直接将这个数据结构作为read字段的一部分),有些数据还可能没有移动到read字段中。
// 对于dirty的操作需要加锁,因为对它的操作可能会有读写竞争。
// 当dirty为空的时候, 比如初始化或者刚提升完,下一次的写操作会复制read字段中未删除的数据到这个数据中。
dirty map[interface{}]*entry
// 当从Map中读取entry的时候,如果read中不包含这个entry,会尝试从dirty中读取,这个时候会将misses加一,
// 当misses累积到 dirty的长度的时候, 就会将dirty提升为read,避免从dirty中miss太多次。因为操作dirty需要加锁。
misses int
}
read的数据结构是:
type readOnly struct {
m map[interface{}]*entry
amended bool // 如果Map.dirty有些数据不在中的时候,这个值为true
}
amended指明Map.dirty中有readOnly.m未包含的数据,所以如果从Map.read找不到数据的话,还要进一步到Map.dirty中查找
对Map.read的修改是通过原子操作进行的
虽然read和dirty有冗余数据,但这些数据是通过指针指向同一个数据,所以尽管Map的value会很大,但是冗余的空间占用还是有限的。
readOnly.m和Map.dirty存储的值类型是*entry,它包含一个指针p, 指向用户存储的value值
type entry struct {
p unsafe.Pointer // *interface{}
}
p 有三种值
1. nil: entry已被删除了,并且m.dirty为nil
2. expunged: entry已被删除了,并且m.dirty不为nil,而且这个entry不存在于m.dirty中
3. entry是一个正常的值
Load
加载方法,也就是提供一个键key,查找对应的值value,如果不存在,通过ok反映
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 1.首先从m.read中得到只读readOnly,从它的map中查找,不需要加锁
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 2. 如果没找到,并且m.dirty中有新数据,需要从m.dirty查找,这个时候需要加锁
if !ok && read.amended {
m.mu.Lock()
// 双检查,避免加锁的时候m.dirty提升为m.read,这个时候m.read可能被替换了。
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 如果m.read中还是不存在,并且m.dirty中有新数据
if !ok && read.amended {
// 从m.dirty查找
e, ok = m.dirty[key]
// 不管m.dirty中存不存在,都将misses计数加一
// missLocked()中满足条件后就会提升m.dirty
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}
这里有两个值的关注的地方。一个是首先从m.read中加载,不存在的情况下,并且m.dirty中有新数据,加锁,然后从m.dirty中加载。
二是这里使用了双检查的处理。判断read.amended的过程并不是原子的,可能在加锁过后,dirty提升为了m.read
可以看到,如果我们查询的键值正好存在于m.read中,无须加锁,直接返回,理论上性能优异。即使不存在于m.read中,经过miss几次之后,m.dirty会被提升为m.read,又会从m.read中查找。所以对于更新/增加较少,加载存在的key很多的case,性能基本和无锁的map类似。
下面看看m.dirty是如何被提升的。 missLocked方法中可能会将m.dirty提升。
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
// 原子更新read,再次期间会调用runtime_procPin()设置为不可抢占,更新完成后取消
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
Store
func (m *Map) Store(key, value interface{}) {
// 如果m.read存在这个键,并且这个entry没有被标记删除,尝试直接存储。
// 因为m.dirty也指向这个entry,所以m.dirty也保持最新的entry。
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
// 如果`m.read`不存在或者已经被标记删除
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
if e.unexpungeLocked() { //标记成未被删除
m.dirty[key] = e //m.dirty中不存在这个键,所以加入m.dirty
}
e.storeLocked(&value) //更新
} else if e, ok := m.dirty[key]; ok { // m.dirty存在这个键,更新
e.storeLocked(&value)
} else { //新键值
if !read.amended { //m.dirty中没有新的数据,往m.dirty中增加第一个新键
m.dirtyLocked() //从m.read中复制未删除的数据
m.read.Store(readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value) //将这个entry加入到m.dirty中
}
m.mu.Unlock()
}
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
// 将已经删除标记为nil的数据标记为expunged
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}
以上操作都是先从操作m.read开始的,不满足条件再加锁,然后操作m.dirty。
Store可能会在某种情况下(初始化或者m.dirty刚被提升后)从m.read中复制数据,如果这个时候m.read中数据量非常大,可能会影响性能
Delete
func (m *Map) Delete(key interface{}) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
delete(m.dirty, key)
}
m.mu.Unlock()
}
if ok {
e.delete()
}
}
同样,删除操作还是从m.read中开始, 如果这个entry不存在于m.read中,并且m.dirty中有新数据,则加锁尝试从m.dirty中删除。
注意,还是要双检查的。 从m.dirty中直接删除即可,就当它没存在过,但是如果是从m.read中删除,并不会直接删除,而是打标记
func (e *entry) delete() (hadValue bool) {
for {
p := atomic.LoadPointer(&e.p)
// 已标记为删除
if p == nil || p == expunged {
return false
}
// 原子操作,e.p标记为nil
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
return true
}
}
}
Range
因为for … range map是内建的语言特性,所以没有办法使用for range遍历sync.Map, 但是可以使用它的Range方法,通过回调的方式遍历
func (m *Map) Range(f func(key, value interface{}) bool) {
read, _ := m.read.Load().(readOnly)
// 如果m.dirty中有新数据,则提升m.dirty,然后在遍历
if read.amended {
//提升m.dirty
m.mu.Lock()
read, _ = m.read.Load().(readOnly) //双检查
if read.amended {
read = readOnly{m: m.dirty}
m.read.Store(read)
m.dirty = nil
m.misses = 0
}
m.mu.Unlock()
}
// 遍历, for range是安全的
for k, e := range read.m {
v, ok := e.load()
if !ok {
continue
}
if !f(k, v) {
break
}
}
}
Range方法调用前可能会做一个m.dirty的提升,不过提升m.dirty不是一个耗时的操作。
参考
https://zhuanlan.zhihu.com/p/399150710 https://colobu.com/2017/07/11/dive-into-sync-Map/ https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-sync-primitives/